☰
Explorar
Iniciar sesión
Crear una nueva cuenta
Pubblicare
×
Descargar
No category
Slide 1
English Syntax
CS 236 – Discrete Mathematics
Chapter 8: Language Acquisition
Working with Writers of English as a Second Language
The Grammar – Translation Method /Classical Method
Formal Languages and Automata Theory
Tentative Unit 1 Schedule
Improving students’ reading & writing skills for IGCSE E2L
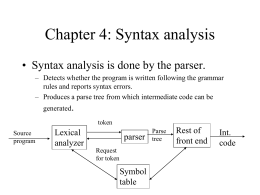
Chapter 4: Syntax analysis
Syntax
Document
How to write the WORST paper ever
Document
CSE 142 Python Slides - Building Java Programs
GRAMMAR WARM-UPS First Six Weeks
Slide 1
BNF Grammar - University of Pennsylvania
Curry
Chapter 7
Slide 1
How to convert a left linear grammar to a right linear …
Agents That Communicate