☰
Explorar
Iniciar sesión
Crear una nueva cuenta
Pubblicare
×
Descargar
No category
Slide 1
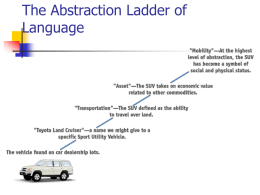
The Abstraction Ladder of Language
投影片 1
Eurovoc presentation
Document
European Thesaurus on International Relations and …
Subject Analysis - University of the Philippines Mindanao
Overview
Chapter 2 PPT
Pay No Attention to the Man Behind the Curtain
What is an ontology, then?
Lesson 9 Day 3
ARMA Filing Rules
Document
Slide 1
Multilingual and cross-lingual news topic tracking
DINI and the Berlin declaration
Information Organization and Retrieval
The Belgian Bilingual Biclassified thesaurus
Две уникальные системы классификации в астрономии: …
Slide 1
Issues in Indexing in the Philippines
Automating Gene Indexing at JAX