☰
Explorar
Iniciar sesión
Crear una nueva cuenta
Pubblicare
×
Descargar
No category
decsai.ugr.es
PASOS PARA POSTULAR
PRE REGISTRO DE EGRESADOS
Document
imágenes locas
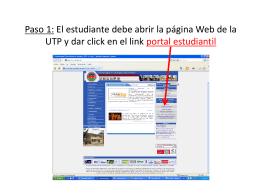
Paso 1. Abrir pagina Web UTP, link portal estudiantil
Slide 1
No Slide Title
JuEgOS vISuAlEs
Flashback..