☰
Explorar
Iniciar sesión
Crear una nueva cuenta
Pubblicare
×
Descargar
No category
XPath 2.0
Week 4 - Earth & Planetary Sciences
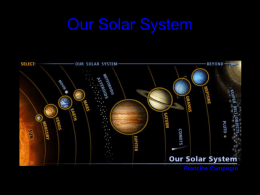
Our Solar System - Pinellas County Schools
Document
History of Astronomy
The Odyssey, Greek Mythology, and Classicism
Las Planetas
Template
E.T. Call home?
XPath
MONADIC DATALOG