☰
Explorar
Iniciar sesión
Crear una nueva cuenta
Pubblicare
×
Descargar
No category
Question Answering at CLEF 2012
Why Do They Do That? Understanding Dementia & How
Sep. 2009
Integrated working in front line services IDeA and ContinYou
Alzheimer’s Disease
Research Powerpoint for Chapters
عرض تقديمي في PowerPoint
Stage 1
Neurociencias copia - Fundacion Duques de Soria
Research Powerpoint for Chapters - UW
Fact Sheet: Suicide and Assisted Suicide
Title of Presentation Arial 50pt Bold
Alzheimer’s Disease - The Evergreen State College
Document
Slide 1
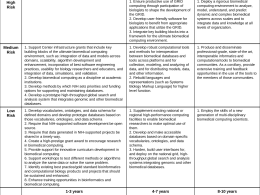
Major Trends in Biomedical Research
Introduction to the PCT System
February 2004 Maintain Your Brain Overview
November is Alzheimer`s Disease Awareness Month
Cellular and molecular mechanisms of brain aging
Retrogenesis theory in Alzheimer`s disease
Team290 - Cerino Zegna
Slide 1