☰
Explorar
Iniciar sesión
Crear una nueva cuenta
Pubblicare
×
Descargar
No category
Document
www.crf-usa.org What We Do What We Believe Why We Do It
Document
INTRODUCTION TO ARTIFICIAL INTELLIGENCE
SURF/CDAS Seminar 25th October 2007
Automatic Speech Recogniton: Generating Lexicons for …
Conditional Random Fields
Inducing Information Extraction Systems for New …
An Introduction to CDISC - presentation
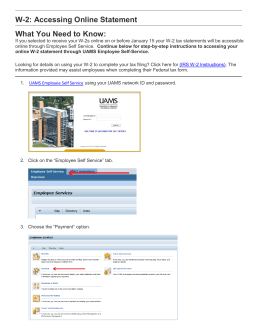
W-2: Accessing Online Statement What You Need to Know
Document
DISCLOSURE NOTICE - University of Cincinnati
Spelling Rules
IT for Emerging Economies
The Google File System
How to improve your memory: Mnemonic Devices
Bild 1
Syntax - University of Washington
Headertitel
homepage.ntlworld.com
投影片 1
Presentation title (on one or two lines)
CDISC SDTM Implementation Process