☰
Explorar
Iniciar sesión
Crear una nueva cuenta
Pubblicare
×
Descargar
No category
Document
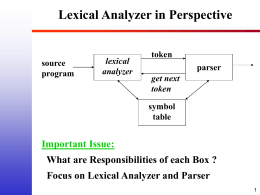
Chapter 3: Lexical Analysis
Information technology foundations
Diapositiva 1
Document
Document
Critical Facts - University of Delaware
COMP 122 - Intro - Computer Science
Lecture 4: Lexical Analysis II: From REs to DFAs
Document
Languages and Finite Automata
Languages and Finite Automata
Lexical Analysis - The Blavatnik School of Computer Science
Document
Languages and Finite Automata
File Management in C
Document
Chapter 4
Working with Writers of English as a Second Language
Chapter 1
Language in Space and Time
COMP 1001: Introduction to Computers for
Document