☰
Explorar
Iniciar sesión
Crear una nueva cuenta
Pubblicare
×
Descargar
Ingeniería
Track E0 AfNOG workshop April 23
Slide 1
Chapter 1 Vocabulary (La estacion de ferrocarril)
Slide 1
Documentación contable
Vocabulary Unit
PowerPoint Template
Slide 1
Slide 1
Presentacion SNMP GoldMaster
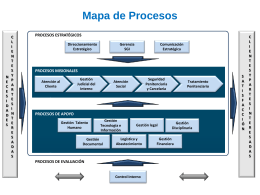
mapa de procesos inpec
Diapositiva 1 - ARCAL | IAEA
SOLIS ALVAREZ CAMILO JAVIER 28-03-2014
HERRAMIENTAS DE ADMINISTRACION Y MONITOREO DE …