☰
Explorar
Iniciar sesión
Crear una nueva cuenta
Pubblicare
×
Descargar
No category
El Simulador SPIM (segunda parte)
Optimización de Software (segunda parte)
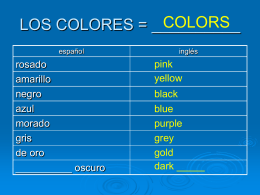
La Ropa y Los Colores - Señora Holmes - Español -
Qué esperar de una presentación oral
TEMA V COMO COMUNICARSE A TRAVES DE LA …
La Ropa y Los Colores
CAMBIO ORGANIZACIONAL
INTRODUCCIÓN A LA INVESTIGACIÓN DE OPERACIONES (I
LA FUGA DE CEREBROS
Unidad 1. La empresa y la cadena de suministro
TEMA: LA FAMILIA - EDFU 3001 / FrontPage