☰
Explorar
Iniciar sesión
Crear una nueva cuenta
Pubblicare
×
Descargar
No category
Data Streams
Data Management for XML: Research Directions
Computer Software
BT Wholesale CIO - CRM B2B Options
Spatiotemporal Data and Sensor Networks Research at the
Giannis Combe
Sensor Network Querying - Computer Science and …
Document
Slide 1
INTEGRATED NAVIGATION SYSTEMS
An XML Introduction
Sensor Networks - Gordon College
Document
Content Integration for E
S95 Arial, Bld, YW8, 37 points, 105% line spacing
Presentation
XML to Database Mapping - Home | Georgia State University
슬라이드 1 - Yonsei
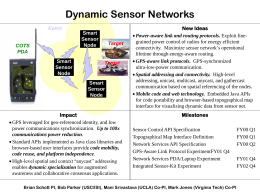
Dynamic Sensor Networks
XML Data Management - University of Houston
Zigbee Nation - University of Colorado Boulder
Office Open XML Packaging
Slide 1