☰
Explorar
Iniciar sesión
Crear una nueva cuenta
Pubblicare
×
Descargar
No category
Trees - NUS School of Computing
2012-02-16 Minutes - San Francisco Bay Area BA-PIER
The Challenge: To Create More Value in All Negotiations
Long Beach City Auditor Laura Doud | www
Trees
Office of International Students and Scholars (OISS) Wayne State
Document
Easy Optimizations
Application Guide - Berkeley International Office
Third Party Web Tracking Policy and Technology
An Introduction to Machine Translation
Comparación de secuencias
Pre-nuclear accents
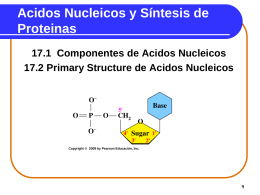
Nucleic Acids
CHAPTER 5: Public-key cryptography
1. History - Stanford University
Introduction of Algorithm and its Analysis
Handling Translation Divergences in Generation
CHAPTER 5 Gene Expression: Transcription