☰
Explorar
Iniciar sesión
Crear una nueva cuenta
Pubblicare
×
Descargar
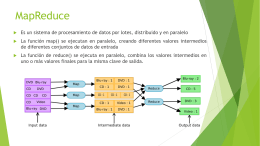
No category
Una Arquitectura Distribuida Tolerante a Fallos para un
Document
Diapositiva 1 - mi-tecnologia
Slide 1
Presentación de PowerPoint
Ponencia
Introducción Apache WEB Server
EXTRAVISIBILIDAD EXTERIOR CARTEL REVISTERO CIF NIF
ESTADISTICAS DE LA UNIDAD DE CUIDADOS
XAMPP
cloud computing