☰
Explorar
Iniciar sesión
Crear una nueva cuenta
Pubblicare
×
Descargar
Ingeniería
Document
Diapositiva 1 - profesorisaacgarciariosestuamigo
Document
Más información - I.T. de Sur de Nayarit
Protocolos de Sondeo
Document
Slide 1
Charla-1 Procesador de texto arreglado (662290)
Ronnie Dave - WordPress.com
Memorias
Radar de Detección
Guia 2. Unidades de Medidas
r2000 - Facultad de Informática
Presentación de PowerPoint
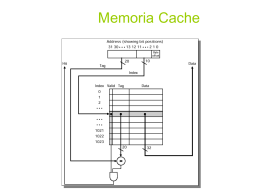
Cache Asociativa por Conjuntos
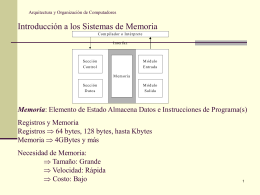
Arquitectura y Organización de Computadores
ES2381961A1 - Universidad de Cantabria
Tema 1 - mips-2010 - Datapath