☰
Explorar
Iniciar sesión
Crear una nueva cuenta
Pubblicare
×
Descargar
No category
Information System for Comparative Analysis of Legume
Chapter 15 - Alcohol, Other Drugs, and Driving - Lincoln
Honors Math 2 Name: Triangle Inequality and Hinge Theorem Date
Hardcore Drunk Driving - National District Attorneys Association
Is It Matter?
GPMMA Options v2
Daily Lesson Plan - Personal Websites
GigaProbes™ Accessory Ordering Part Number: GPMMA Price
blood alcohol concentration
TEAM Training Presentation
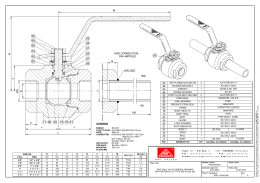
DDN h N M = = L END CONNECTION: SW+NIPPLES G J F
Manual for GMO investigation in food samples - Mettnau
OIB presentation 08
For Tektronix, Inc. TDR Oscilloscopes
Hand Held Probes for Tektronix TDR Oscilloscopes
MSO/DPO5000 Series Oscilloscopes
DEMA TITAN WAREWASH CONTROL T-812 & T-813
dp10 folleto detallado
Slide 1
Making Meaning through Grammar: 'This Bread I Break' by
Student Learning Objectives
Introduction to PSP - Poznań University of Technology
Adaptive Enterprises - Niwot Ridge Consulting