☰
Explorar
Iniciar sesión
Crear una nueva cuenta
Pubblicare
×
Descargar
No category
Automatic Speech Recognition . ppt
5P – Science Pitch and Volume 1. Use the following 2 links to learn
Unit 5F: Changing sound
Networking - Internship and Career Center
to view details
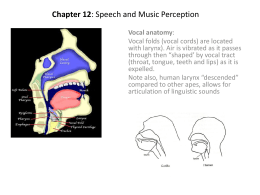
Chapter 12: Speech and Music Perception
lecture 3 - Fredonia.edu
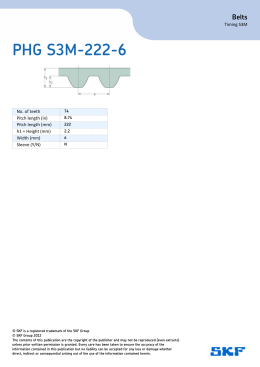
PHG S3M-222-6
Document
Speech without Pitch - Carnegie Mellon University
Fundamentals of Phonology
Document
Slide 1
Chapter 3
Realizational Differences between Questions and …
Slide 1
Document
Thinking - Valencia High School
No Slide Title
Turn-taking in Mandarin Dialogue: Interactions of Tone …
Speech Recognition
Audio in the Free Field: Virtual Reality Displays and
Characterizing and Recognizing Spoken Corrections