☰
Explorar
Iniciar sesión
Crear una nueva cuenta
Pubblicare
×
Descargar
No category
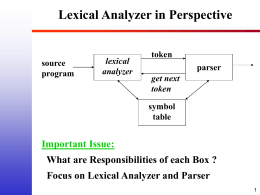
Lexical Analysis and Scanning
Slides for Rosen, 5th edition
ECE-548 Sequential Machine Theory
Chapter 3: Lexical Analysis
Finate State Machines in Games
Creating new worlds inside the computer
Lexical Analysis - The Blavatnik School of Computer Science
Document
Finite State Machine for Games
Document
Document
Paper presentation
THE STRUCTURE OF ENGLISH
Lexical Analysis - The Blavatnik School of Computer Science
Software Testing Theory and Practice
Slide 1
PowerPoint Template
Document
Concordia University Department of Computer Science
Chapter 10: Compilers and Language Translation
What is Language Acquisition?
Chapter #8: Finite State Machine Design Contemporary …
JQL : The Java Query Language