☰
Explorar
Iniciar sesión
Crear una nueva cuenta
Pubblicare
×
Descargar
No category
Engineering Distributed Graph Algorithms in PGAS …
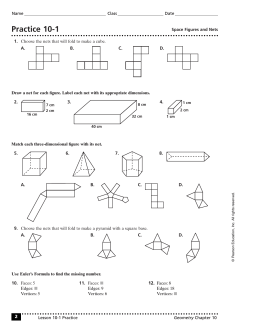
Practice 10-1
Weighted Graphs Single-Source Shortest Paths Greedy Approach to
English language learning activity using spoken language and
Introductory elements - University of L`Aquila
Space Figures and Cross Sections
Open64's Role in the Many Core Era
Complexity & Communication
Welcome guide for exchange students
“Adversarial Deletion in Scale Free Random Graph Process” by A.D.
COMPUTER AND DATA SECURITY
Document
Recitation 10
C H A P T E R
Information Incoming Students 2016-17
Document
Technical Paper Writing
(as a slide show): Planar Graphs
ZhangIPDPS05 - UPC Projects at MTU
Design and Analysis of Algorithms
PPT
Introduction to trees Identifying trees, roots, leaves, vertices, edges
Notes