☰
Explorar
Iniciar sesión
Crear una nueva cuenta
Pubblicare
×
Descargar
No category
Chapter 3 Retrieval Evaluation
沒有投影片標題 - NTU NLPL's Homepage台大自然
Infomaster: An Information Integration Tool
Text Processing
Kernel Canonical Correlation analysis
Pictorial Query by Example PQBE
Our Powers Combined:Query, Pivot, Map
Q2Semantic: A Lightweight Keyword Interface to …
Information Organization and Retrieval
Temporal Query Log Profiling to Improve Web Search …
Text Retrieval Issues - Courses | UC Berkeley School of
Content Integration for E
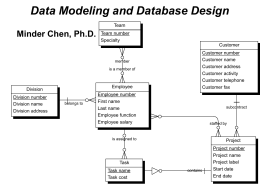
Data Modeling and Database Design
Document
XBRL