☰
Explorar
Iniciar sesión
Crear una nueva cuenta
Pubblicare
×
Descargar
Ciencia
Modelos de Variable Dependiente Binaria -Logit y Probit-
Modelos de Variable Dependiente Binaria
Tema 1
MODELOS DE DEMANDA DE TRANSPORTE
Mixed Logit vs Nested Logit and Probit models
introduccion - DSpace en ESPOL
Diapositiva 1 - Universidad Autónoma de Madrid
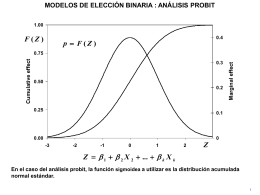
MODELOS DE ELECCIÓN BINARIA : ANÁLISIS PROBIT Como en
Limitaciones del modelo lineal de probabilidad y alternativas de
Unidad 5
C7. Variaciones sobre un Mismo Tema
TALES DE MILETO - Bases biológicas de la
Análisis del consumidor
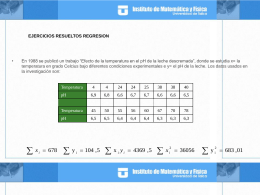
Ejercicios Resueltos Regresion
Diapositiva 1
Diapositiva 1
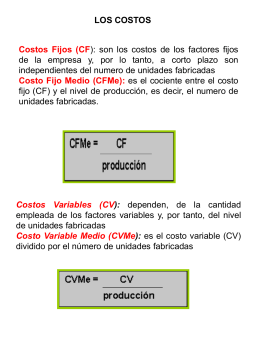
Costo Fijo Medio (CFMe)
Eco y emp-Costos
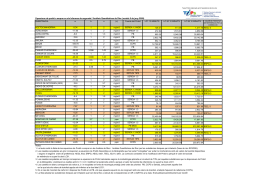
Copia de taula PROBITS final
Diapositiva 1 - SALA DE HISTORIA
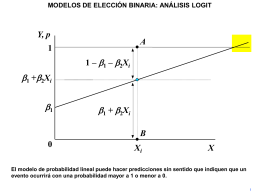
modelos de elección binaria: análisis logit